

INDEX
인덱스는 검색의 효율성을 증대시키기 위해 사용한다. PK(Primary Key)는 자동으로 index가 생성되어 있기 때문에 PK 컬럼은 인덱스를 따로 만들어 줄 필요가 없다. 따라서 인덱스는 기본키가 아닌 일반 컬럼들의 탐색 속도를 위해 존재한다.
그러나 index는 생성 시마다 하드의 용량을 차지하게 되기 때문에, 너무 많이 만들 경우에는 오히려 성능이 떨어질 수 있다.
예시로 사용한 csv 파일은 이곳에서 다운받는다. : https://www.data.go.kr/data/15053384/fileData.do
대전광역시_유성구_구즉도서관도서목록_20221027
대전광역시 유성구 구즉도서관에서 보유하고 있는 도서목록 정보(소장처, 자료실, 등록번호, 설명, 저자, 출판사, 출판년, 청구기호 등)
www.data.go.kr
먼저 지금까지 배운 일반 쿼리문으로 자료를 조회해본다. 자료실이 '어린이실' 인 레코드의 개수는 총 3만 6548개이다.


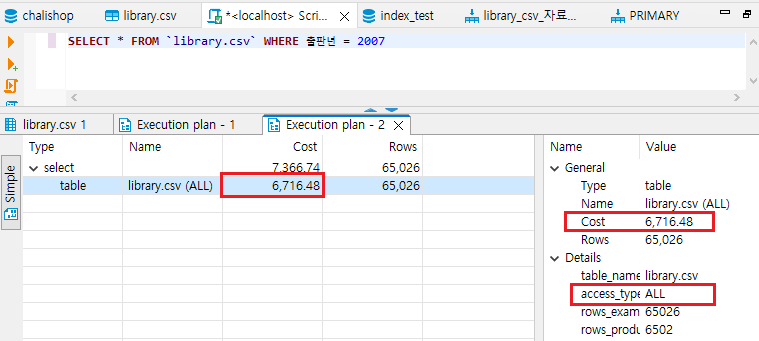
쿼리를 실행하는 데 걸린 시간을 'Cost' 라고 한다. 디비버에서 '실행 계획 보기' 를 클릭하거나 Ctrl+Shift+E를 동시에 누르면 Cost를 확인해볼 수 있다.
access_type는 어떤 방식으로 검색했는지를 나타낸다. 만일 ALL이라고 적혀있다면 모든 행을 스캔하여 검색했다는 뜻이고, ref라고 적혀있다면 인덱스를 사용한 것이다. filtered는 읽은 행과 결과로 출력된 행을 비율로 나타낸 것이다.

인덱스를 만들기 위해서는, 해당 테이블의 Indexes 폴더에서 우클릭을 통해 생성할 수 있다. 처음에는 기본값인 BTree를 사용해본다. '자료실'을 체크하여 인덱스로 설정해 주었다.
CREATE INDEX library_csv_소장처_IDX USING BTREE ON index_test.`library.csv` (소장처);
다시 자료실이 어린이실인 도서를 검색하자, Cost가 현저히 줄어들었음을 알 수 있다. Cost는 작을수록 검색 속도가 빠름을 의미한다. 인덱스를 사용하였으므로 access_type에 ref가 기록되었다.

그러나 반드시 모든 경우에서 인덱스를 사용하는 것은 아니다. sql은 만일 전체 행에 대비하여, 출력할 행의 비율이 20%를 넘기면 index를 사용하는 효율이 적다고 판단해 인덱스를 사용하지 않는다. 부등호를 사용하여 '가' 보다 큰, 즉 모든 자료실의 내용을 출력해보자.

인덱스와 같은 역할을 해주는 기본키(PK) 검색 효율을 보기 위해 기본키를 생성해본다. id라는 이름으로, AUTO_INCREMENT 옵션을 주어 차례로 1씩 증가하는 기본키를 생성해 주었다.
ALTER TABLE `library.csv` ADD COLUMN id int PRIMARY KEY AUTO_INCREMENT

id를 활용해 SELECT문으로 모든 행을 출력하자, 3,298.79라는 Cost가 소요되었다. aaccess_type 밑에 있는 key 값에 PRIMARY가 적혀있는 것을 확인할 수 있다.

인덱스는 한가지의 값이 아닌 여러 값으로도 설정할 수 있는데, 이를 다중 인덱스라고 한다. 인덱스를 생성할 때 # 열에 1, 2라고 적힌 것을 볼 수 있는데 이 값의 순서대로 우선이 된다. 아래 예시에서는 출판사가 1순위이고, 출판년이 2순위인 다중 인덱스를 생성하였다. 다중 인덱스로 출판사가 소리봄이면서, 출판년도는 2007년인 데이터를 출력하는데 걸린 Cost를 살펴보았다.


만일 다중 인덱스로 등록한 요소 중 한 가지만 조건을 주어 SELECT문을 실행하면, 인덱스를 등록할 때 가장 우선순위가 되도록 했던 컬럼만 인덱스로 사용하게 된다. 즉 where 출판사 = 조건 의 경우는 해당 인덱스를 사용하지만, where 출판년 = 조건 의 경우에는 해당 인덱스를 사용하지 않는다. 따라서 카디널리티(구분할 수 있는 정확성 정도)가 높은 것을 다중 인덱스의 앞쪽에 주는 것이 좋다.

Full text index + MATCH(), AGAINST()
%가 들어있는 LIKE 연산자를 사용하면 인덱스를 사용할 수 없게 된다. 이를 위해 만들어진 것이 Full text index이다.
CREATE FULLTEXT INDEX 인덱스명 ON db명.테이블명 (필드명);
Full text index를 생성하면 모든 단어를 추출하여, 해당 단어가 어떤 행에 나왔는지를 인덱스로 생성해둔다. 저장하는 데이터가 영어일 경우 stopwords(is, are, and, or, the 등)들을 제거한 뒤 인덱스를 만들어준다. (한글은 해당 X)
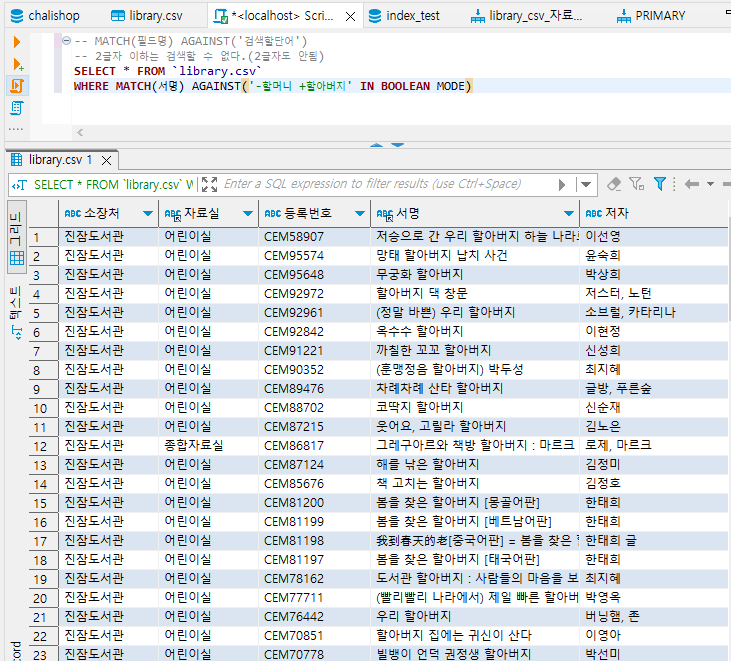
IN NATURAL LANGUAGE MODE가 stopwords를 제거해 달라는 문법인데, 한글을 검색할 때에는 IN BOOLEAN MODE를 사용한다. IN BOOLEAN MODE를 사용할 경우 검색할 키워드에 * 을 사용할 수 있다. *은 %와 유사한 의미로, 검색어를 포함한 모든 단어를 검색해달라는 뜻이다.

띄어쓰기는 OR 연산으로 적용된다. 만일 '할머니 할아버지' 라고 검색하면, '할머니' 또는 '할아버지' 를 가진 도서를 출력해준다.

반드시 들어가야 하는 단어를 검색할 때에는 더하기 기호 '+' 를 사용한다. '+할머니 +할아버지' 라고 검색하면, 할머니와 할아버지라는 단어가 둘 다 들어간 도서만 검색해준다.

반드시 포함되지 않아야 하는 키워드를 넣어줄 때에는 빼기 기호 ' - '를 사용한다.
full text index는 띄어쓰기를 기준으로 단어를 분리하여 인덱스를 생성한다. 그러나 중국어, 일본어 등은 띄어쓰기를 사용하지 않는 언어이다. 이러한 언어를 처리하기 위하여 ngram parser를 이용해 인덱스를 생성할 수 있다.
n-gram parser은 띄어쓰기를 무시하고, 글자를 몇 글자 단위로 잘라서 index를 생성하는 방식이다. 아래와 같은 방법으로 만들어 사용하면 된다.
CREATE FULLTEXT INDEX 인덱스이름 ON 데이터베이스명.테이블명 (필드명) WITH PARSER ngram
'SQL' 카테고리의 다른 글
| [MySQL] 11. Trigger (0) | 2022.12.27 |
|---|---|
| [MySQL] 10. Transaction (0) | 2022.12.27 |
| [MySQL] 8. 날짜 데이터 (datetime Data type과 now(), data_format(날짜,포맷형식)) (0) | 2022.12.26 |
| [MySQL] 7. FUNCTION (0) | 2022.12.26 |
| [MySQL] 6. 프로시저(stored procedure)와 추억 (0) | 2022.12.26 |